|
Xibin Song I'm a research scientist at Tencent XR vision Labs. Before that, I work as senior researcher at Robotics and Autonomous Driving Laboratory (RAL) of Baidu Research in 2018-2022. I did my PhD and Bachelor at Shandong University, where I was advised by Prof. Xueying Qin. During my PhD, I worked as a joint training of Ph.D. student in the Research School of Engineering at the Australian National University in 2015-2016, where I was advised by Prof. Richard Hartley and Prof. Yuchao Dai. |

|
ResearchMy research interests lie in the intersection of 3D computer vision, artificial intelligence, particularly focusing on Perception Technology in Autonomous Driving, 3D AIGC and AR/VR, etc. |
|
Pandora3D: A Comprehensive Framework for High-Quality 3D Shape and Texture Generation
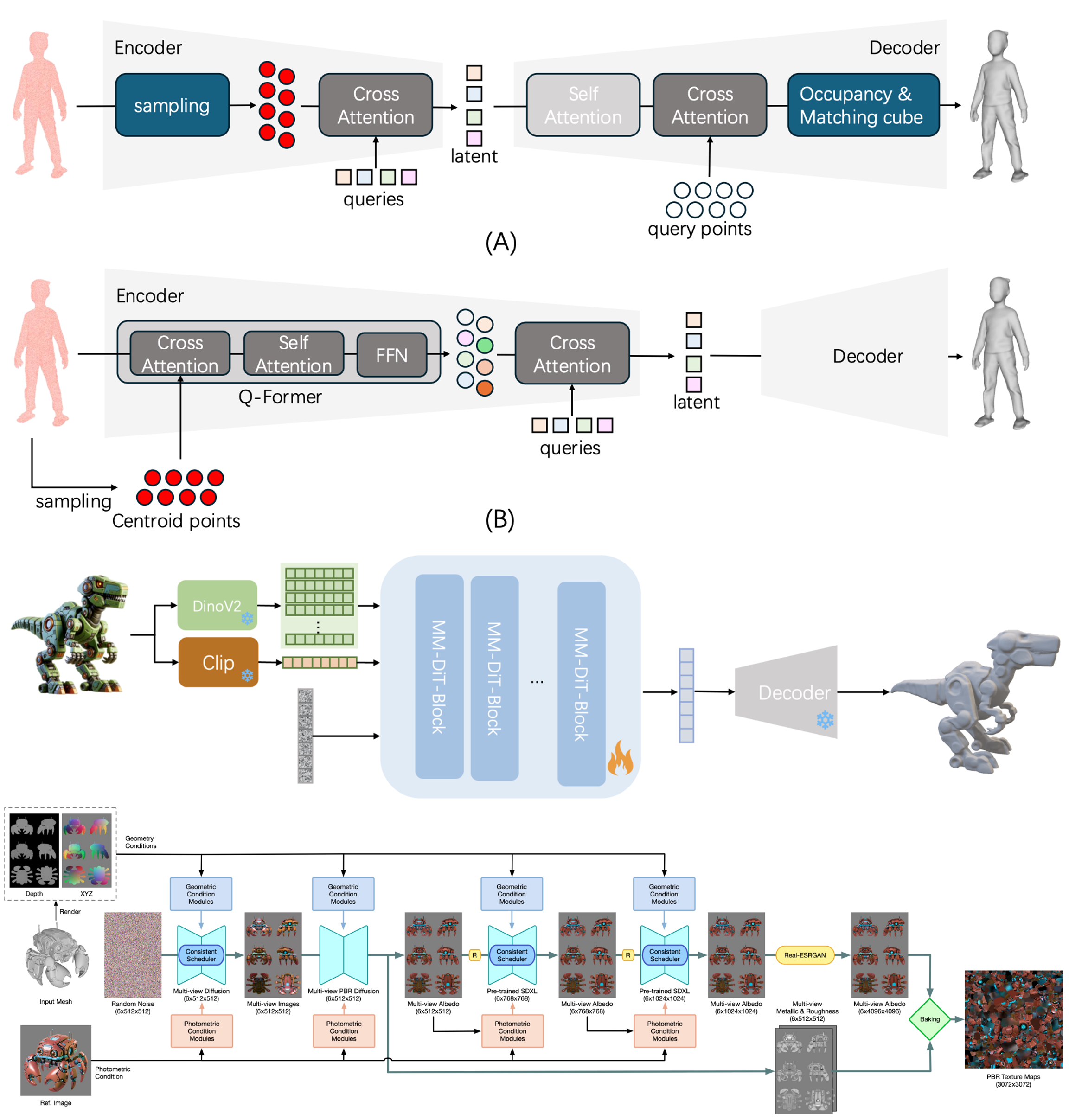
Jiayu Yang, Taizhang Shang, Weixuan Sun, Xibin Song, Ziang Cheng, Senbo Wang, Shenzhou Chen, Weizhe Liu, Hongdong Li, Pan Ji Corresponding author pdf - Arxiv This report presents a comprehensive framework for generating high-quality 3D shapes and textures from diverse input prompts, including single images, multi-view images, and text descriptions. The framework consists of 3D shape generation and texture generation. |
|
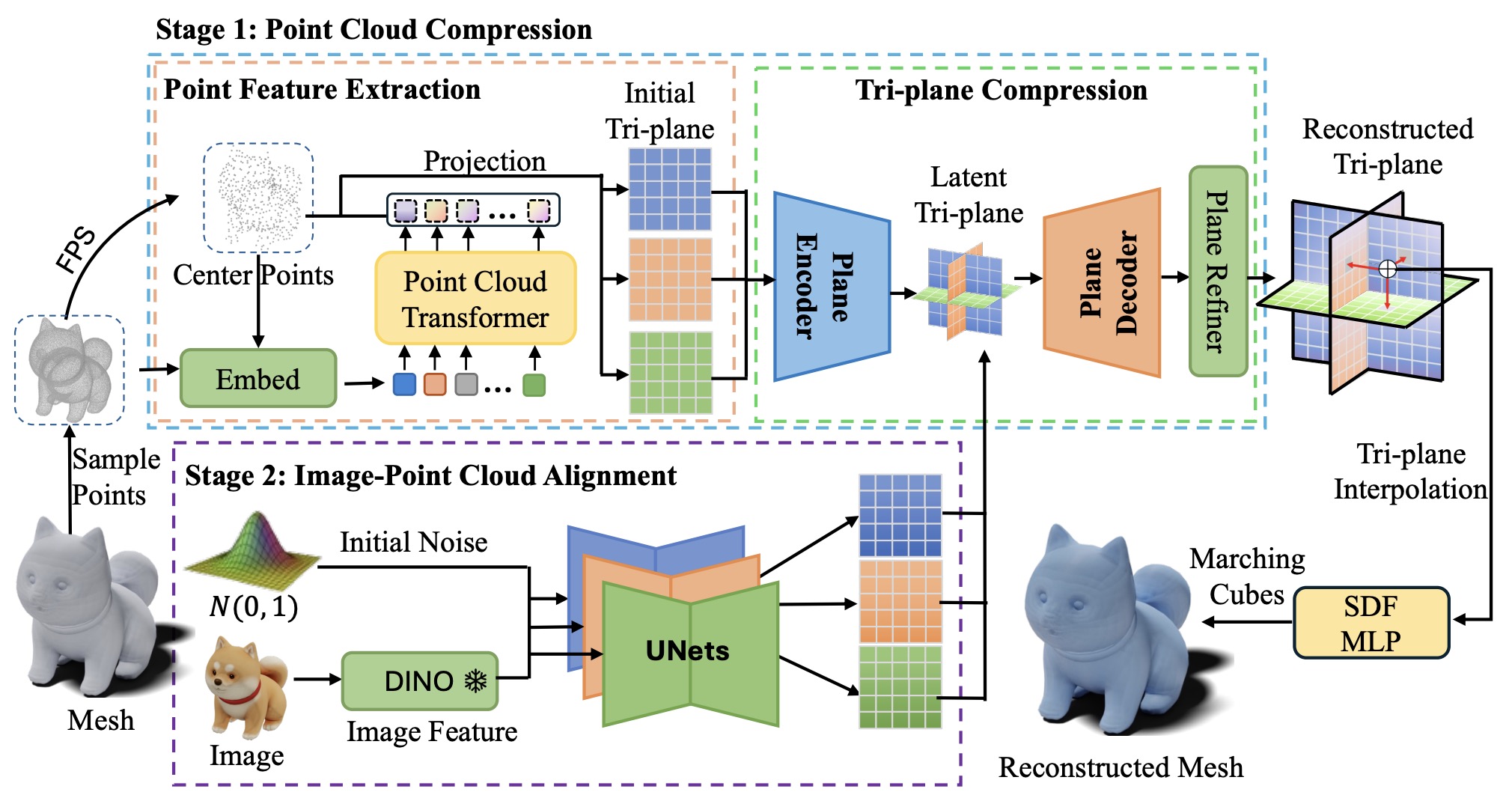
LAM3D: Large Image-Point-Cloud Alignment Model for 3D Reconstruction from Single Image
Ruikai Cui, Xibin Song, Weixuan Sun, Senbo Wang, Weizhe Liu, Shenzhou Chen, Taizhang Shang, Yang Li, Nick Barnes, Hongdong Li, Pan Ji Corresponding author pdf - NIPS2024 Large Image and Point Cloud Alignment Model (LAM3D), which utilizes 3D point cloud data to enhance the fidelity of generated 3D meshes. |
|
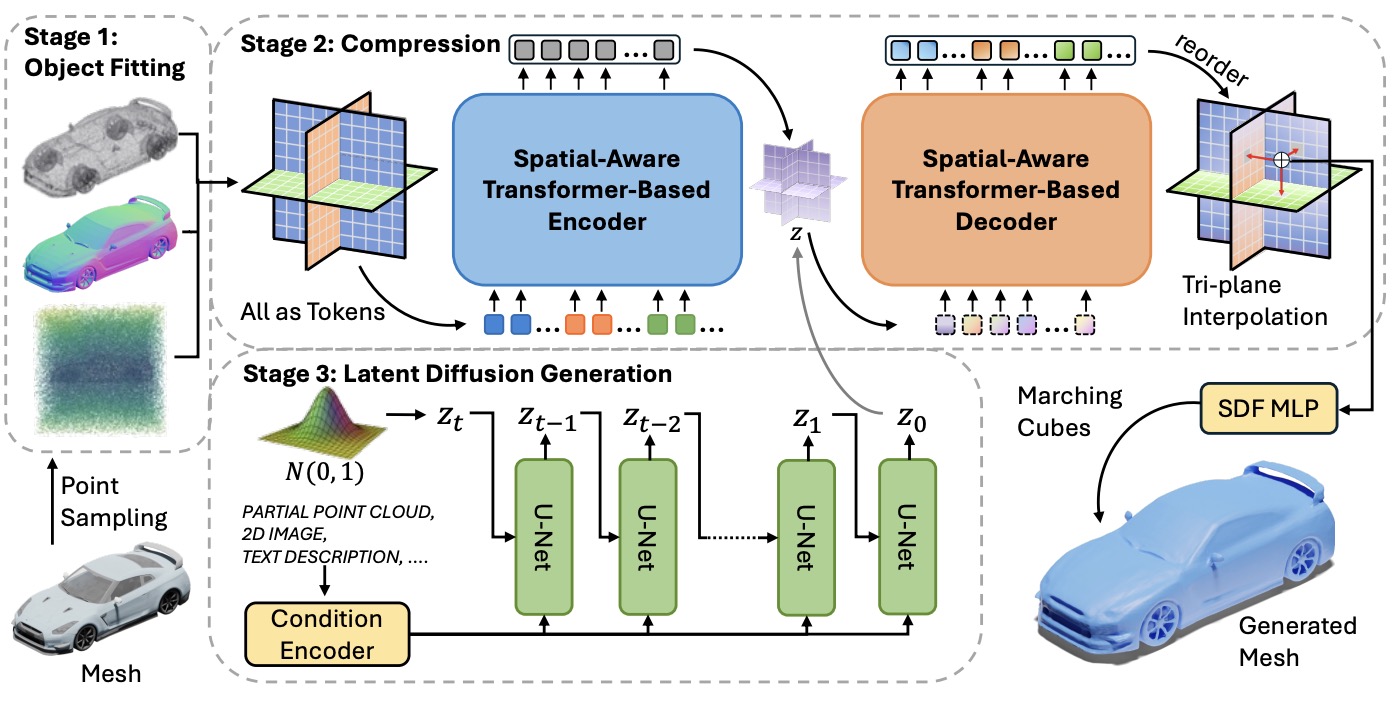
Neusdfusion: A spatial-aware generative model for 3d shape completion, reconstruction, and generation
Ruikai Cui, Weizhe Liu, Weixuan Sun, Senbo Wang, Taizhang Shang, Yang Li, Xibin Song, Han Yan, Zhennan Wu, Shenzhou Chen, Hongdong Li, Pan Ji pdf - ECCV2024 3D shape generation aims to produce innovative 3D content adhering to specific conditions and constraints. Existing methods often decompose 3D shapes into a sequence of localized components, treating each element in isolation without considering spatial consistency. As a result, these approaches exhibit limited versatility in 3D data representation and shape generation, hindering their ability to generate highly diverse 3D shapes that comply with the specified constraints. In this paper, we introduce a novel spatial-aware 3D shape generation framework that leverages 2D plane representations for enhanced 3D shape modeling. |
|
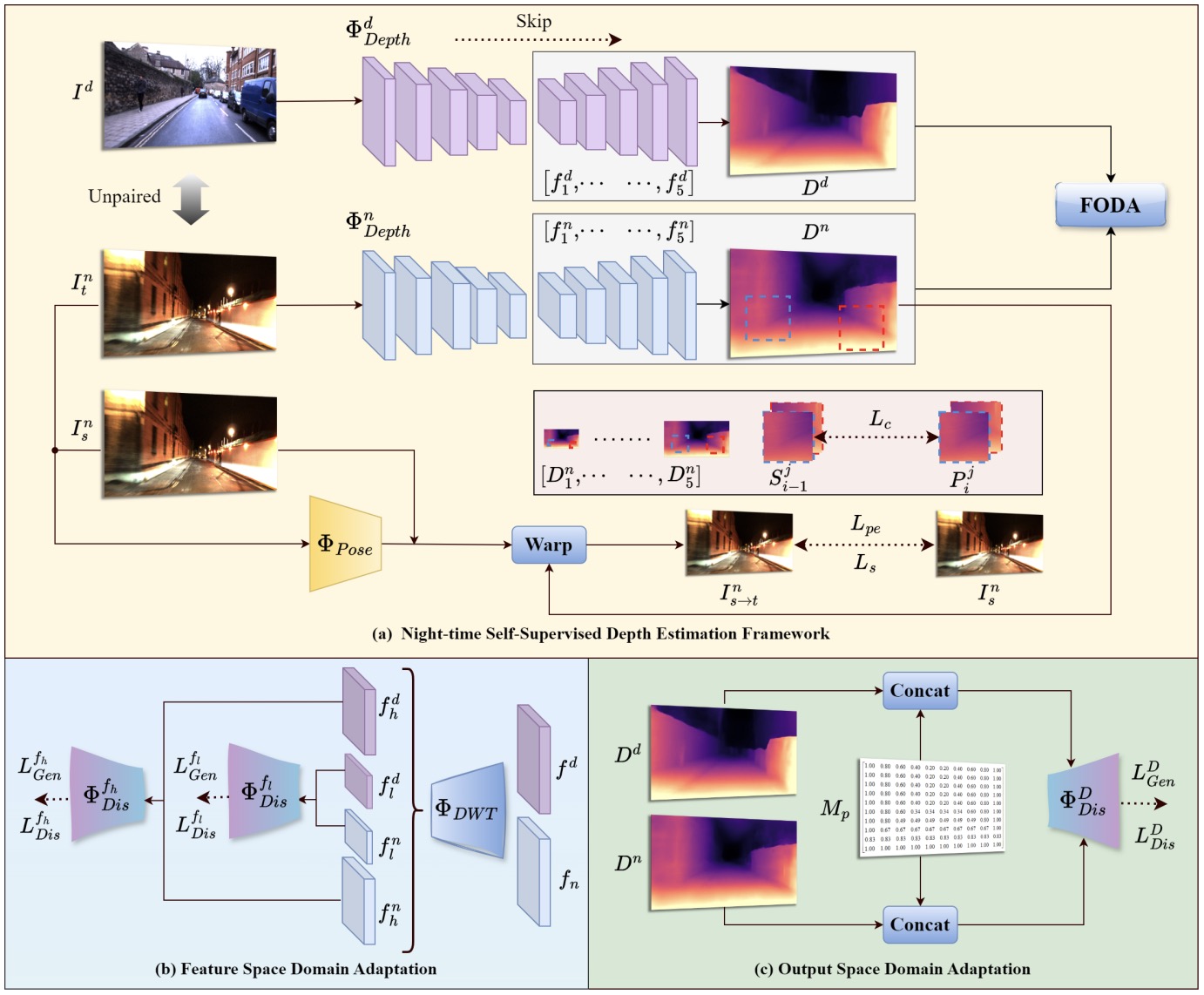
SRNSD: Structure-Regularized Night-Time Self-Supervised Monocular Depth Estimation for Outdoor Scenes
Ruimin Cong, Chunlei Wu, Xibin Song, Wei Zhang, Sam Kwong, Hongdong Li, Pan Ji Corresponding author pdf - IEEE Transactions on Image Processing (2024) Night-time self-supervised Depth Estimation for Outdoor Scenes. |
|
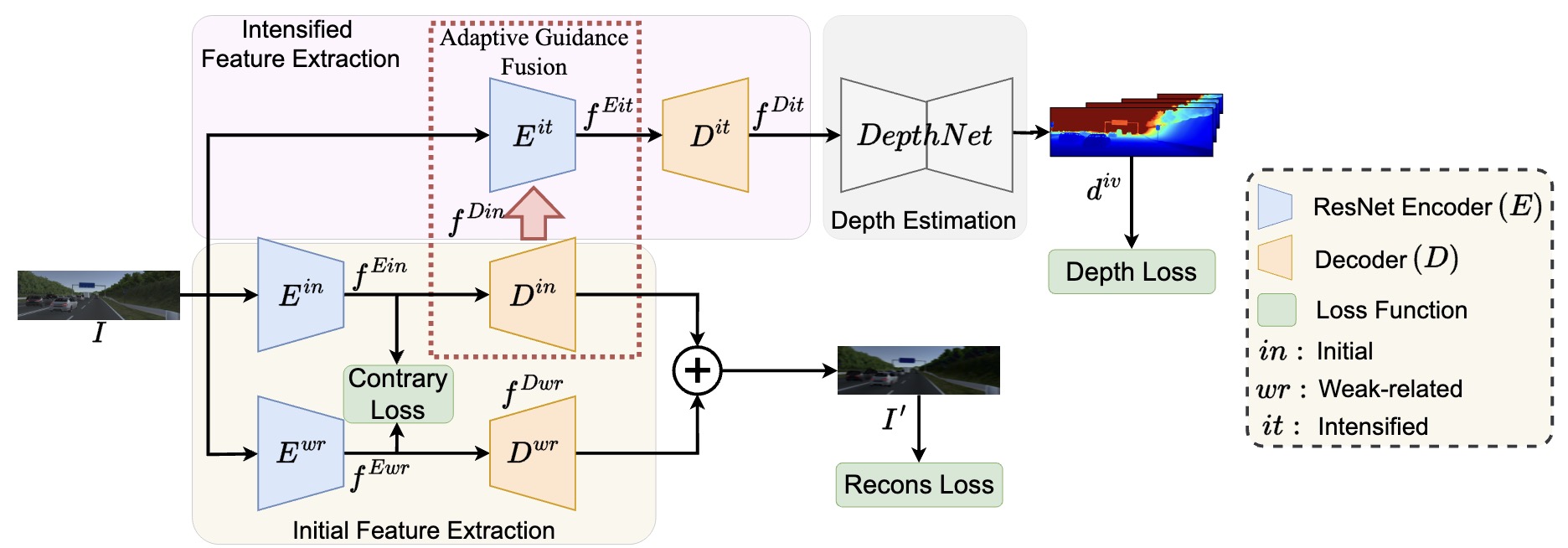
AGDF-Net: learning domain generalizable depth features with adaptive guidance fusion
Lina Liu, Xibin Song, Mengmeng Wang, Yuchao Dai, Yong Liu, Liangjun Zhang Corresponding author pdf -IEEE Transactions on Pattern Analysis and Machine Intelligence (2023) We propose a domain generalizable feature extraction network with adaptive guidance fusion (AGDF-Net) to fully acquire essential features for depth estimation at multi-scale feature levels. |
|
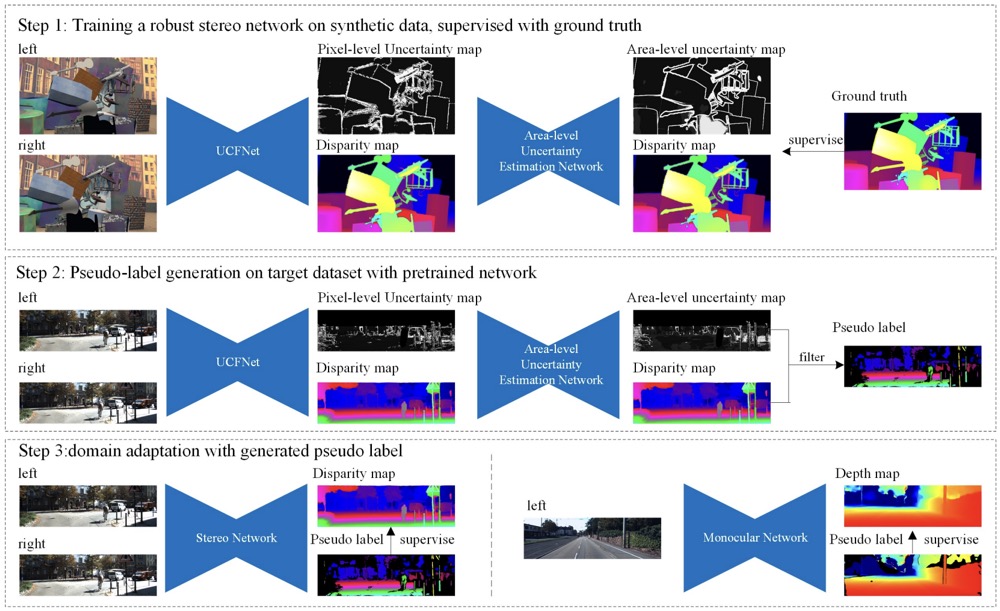
Digging into uncertainty-based pseudo-label for robust stereo matching
Zhelun Shen, Xibin Song, Yuchao Dai, Dingfu Zhou, Zhibo Rao, Liangjun Zhang Corresponding author pdf - IEEE Transactions on Pattern Analysis and Machine Intelligence (2023) We propose to dig into uncertainty estimation for robust stereo matching. |
|
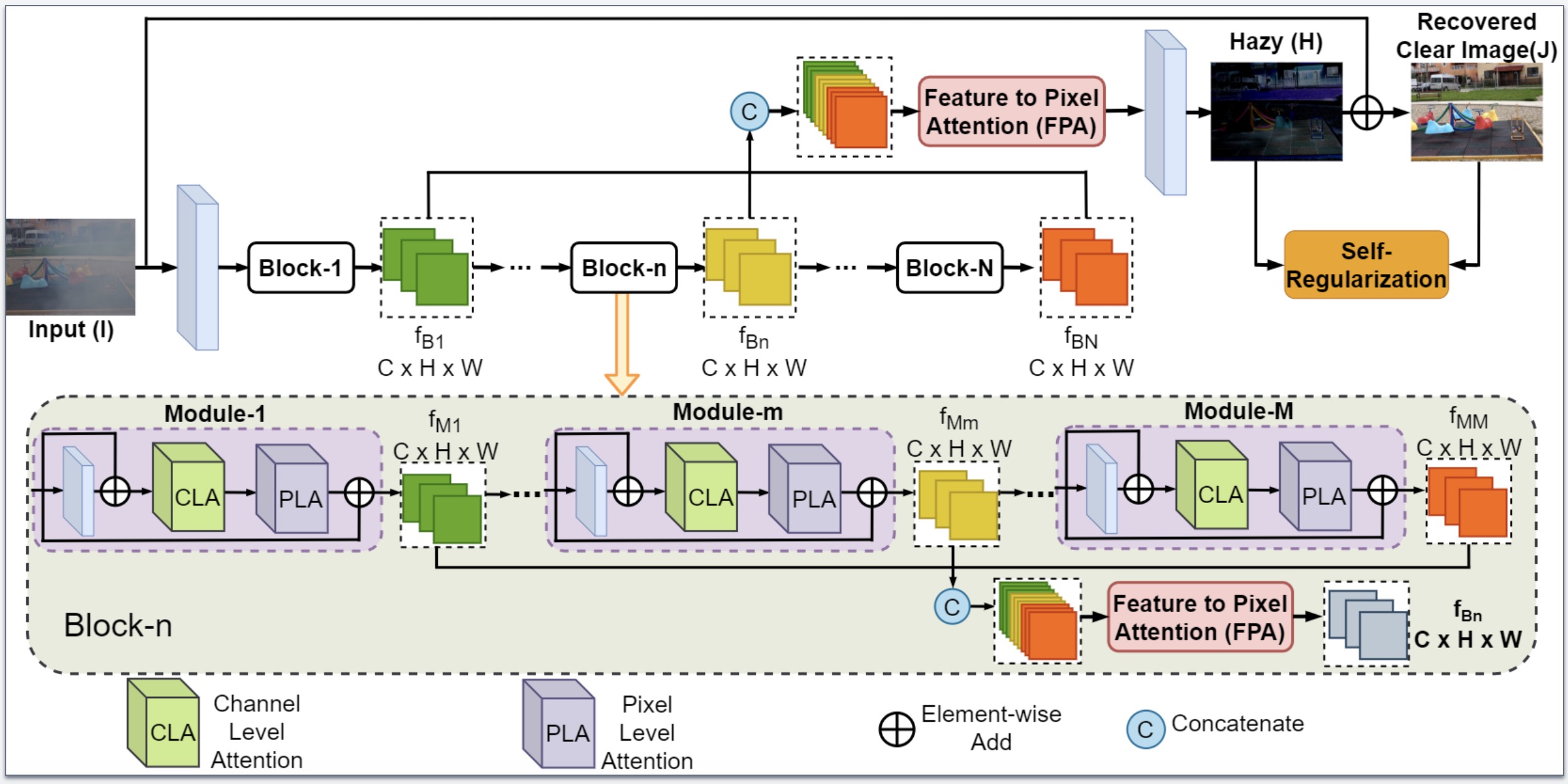
TUSR-Net: triple unfolding single image dehazing with self-regularization and dual feature to pixel attention
Xibin Song, Dingfu Zhou, Wei Li, Yuchao Dai, Zhelun Shen, Liangjun Zhang, Hongdong Li pdf - IEEE Transactions on Image Processing (2023) We propose an end-to-end self-regularized network (TUSR-Net) which exploits the contrastive peculiarity of different components of the hazy image, i.e, self-regularization (SR). |
|
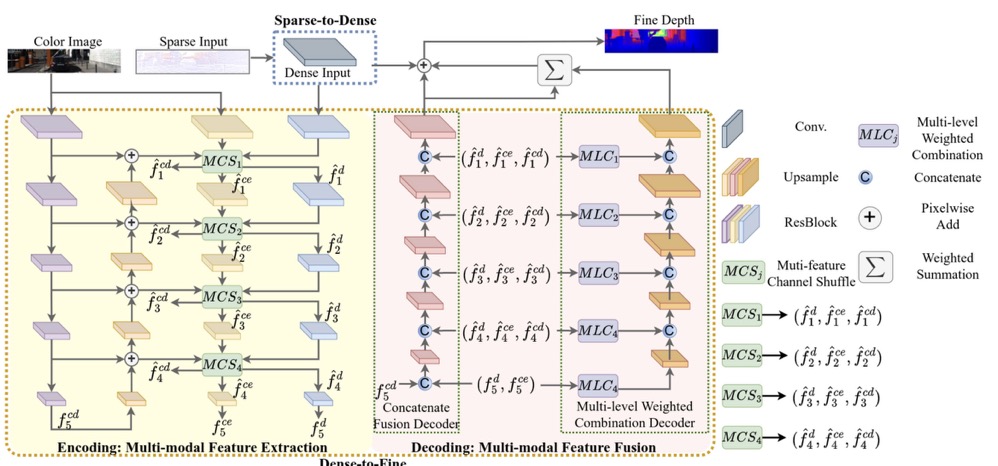
Mff-net: Towards efficient monocular depth completion with multi-modal feature fusion
Lina Liu, Xibin Song, Jiadai Sun, Xiaoyang Lyu, Lin Li, Yong Liu, Liangjun Zhang Corresponding author pdf - RAL (2023) In this work, we propose an efficient multi-modal feature fusion based depth completion framework (MFF-Net), which can efficiently extract and fuse features with different modals in both encoding and decoding processes, thus more depth details with better performance can be obtained. |
|
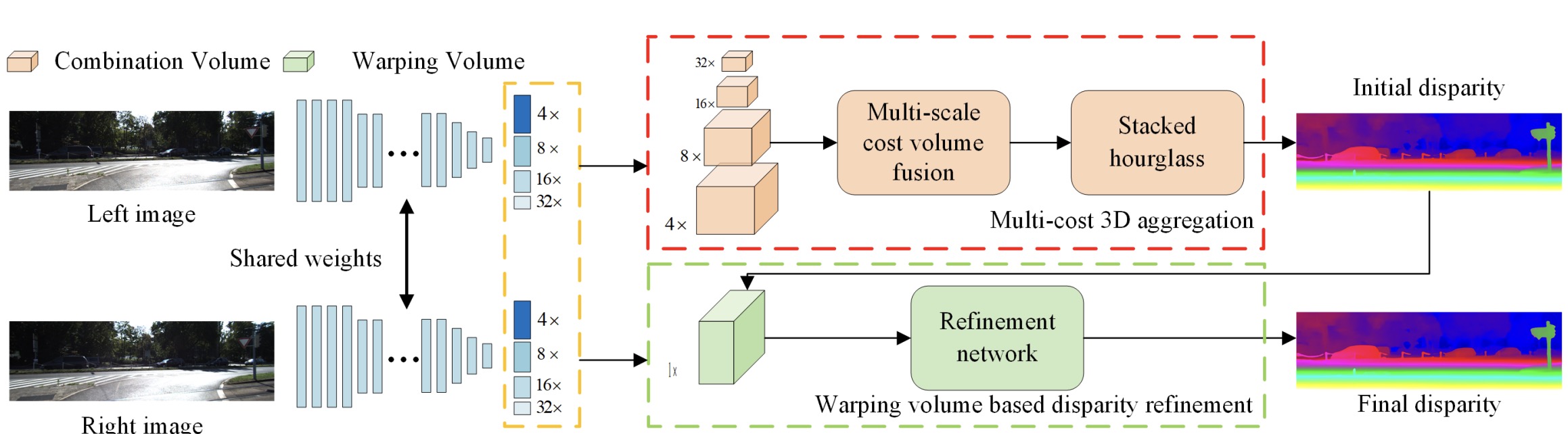
Pcw-net: Pyramid combination and warping cost volume for stereo matching
Zhelun Shen, Yuchao Dai, Xibin Song, Zhibo Rao, Dingfu Zhou, Liangjun Zhang Corresponding author pdf - ECCV (2022) We propose PCW-Net, a Pyramid Combination and Warping cost volume-based network to achieve good performance on both crossdomain generalization and stereo matching accuracy on various benchmarks. |
|
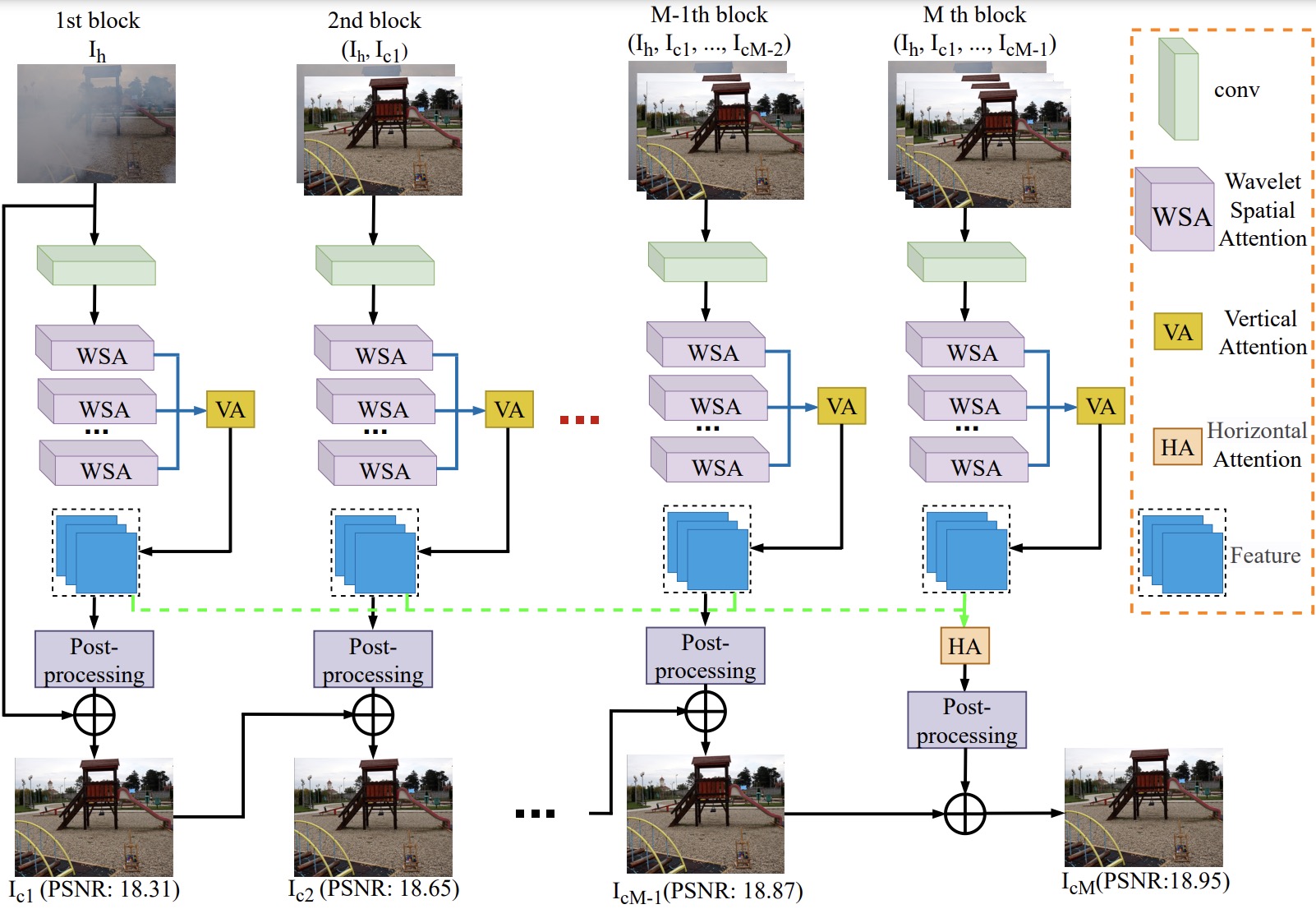
WSAMF-Net: Wavelet spatial attention-based MultiStream feedback network for single image dehazing
Xibin Song, Dingfu Zhou, Wei Li, Haodong Ding, Yuchao Dai, Liangjun Zhang pdf - IEEE Transactions on Circuits and Systems for Video Technology (2022) A wavelet spatial attention based multi-stream feedback network (WSAMF-Net) is proposed for effective single image dehazing. |
|
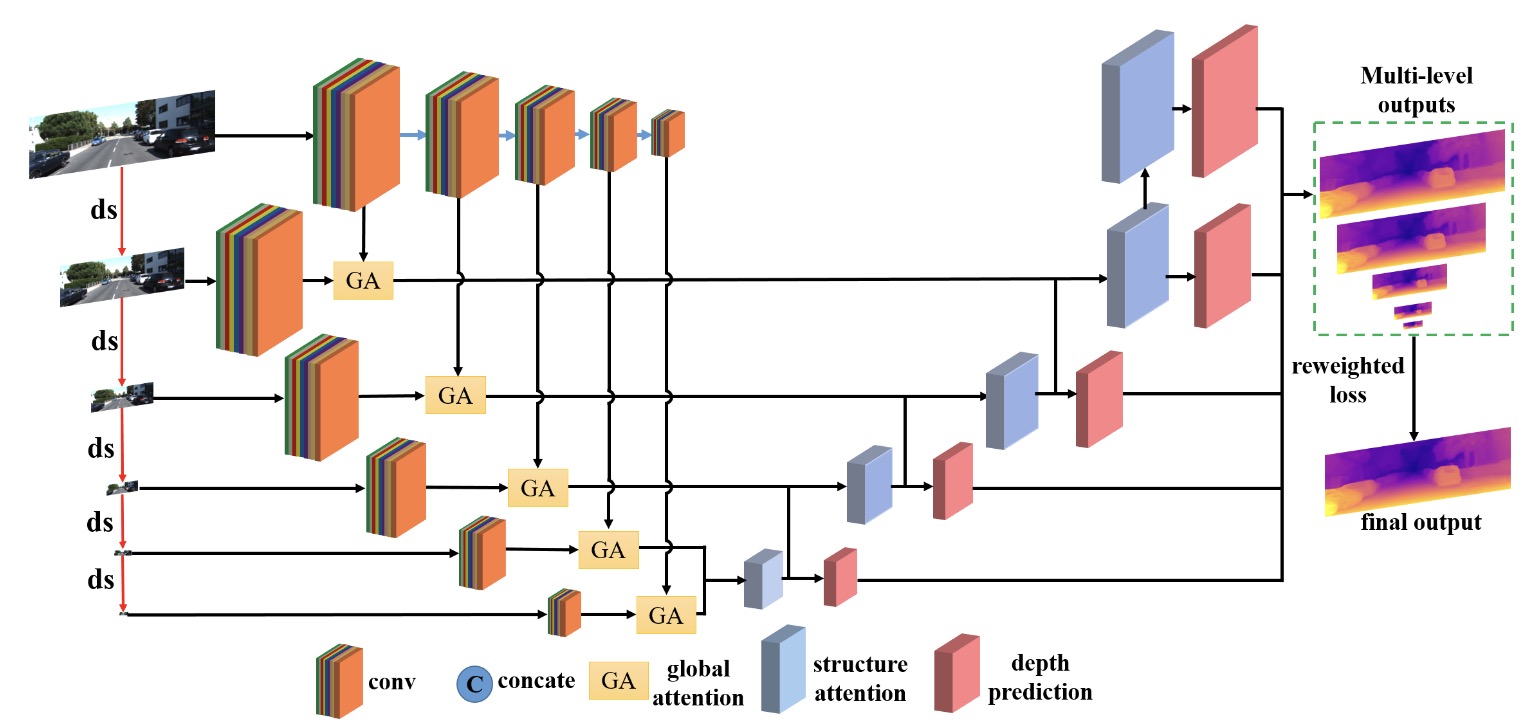
MLDA-Net: Multi-level dual attention-based network for self-supervised monocular depth estimation
Xibin Song, Wei Li, Dingfu Zhou, Yuchao Dai, Jin Fang, Hongdong Li, Liangjun Zhang pdf - IEEE Transactions on Image Processing (2021) We propose a novel framework, named MLDA-Net, to obtain per-pixel depth maps with shaper boundaries and richer depth details. |
|
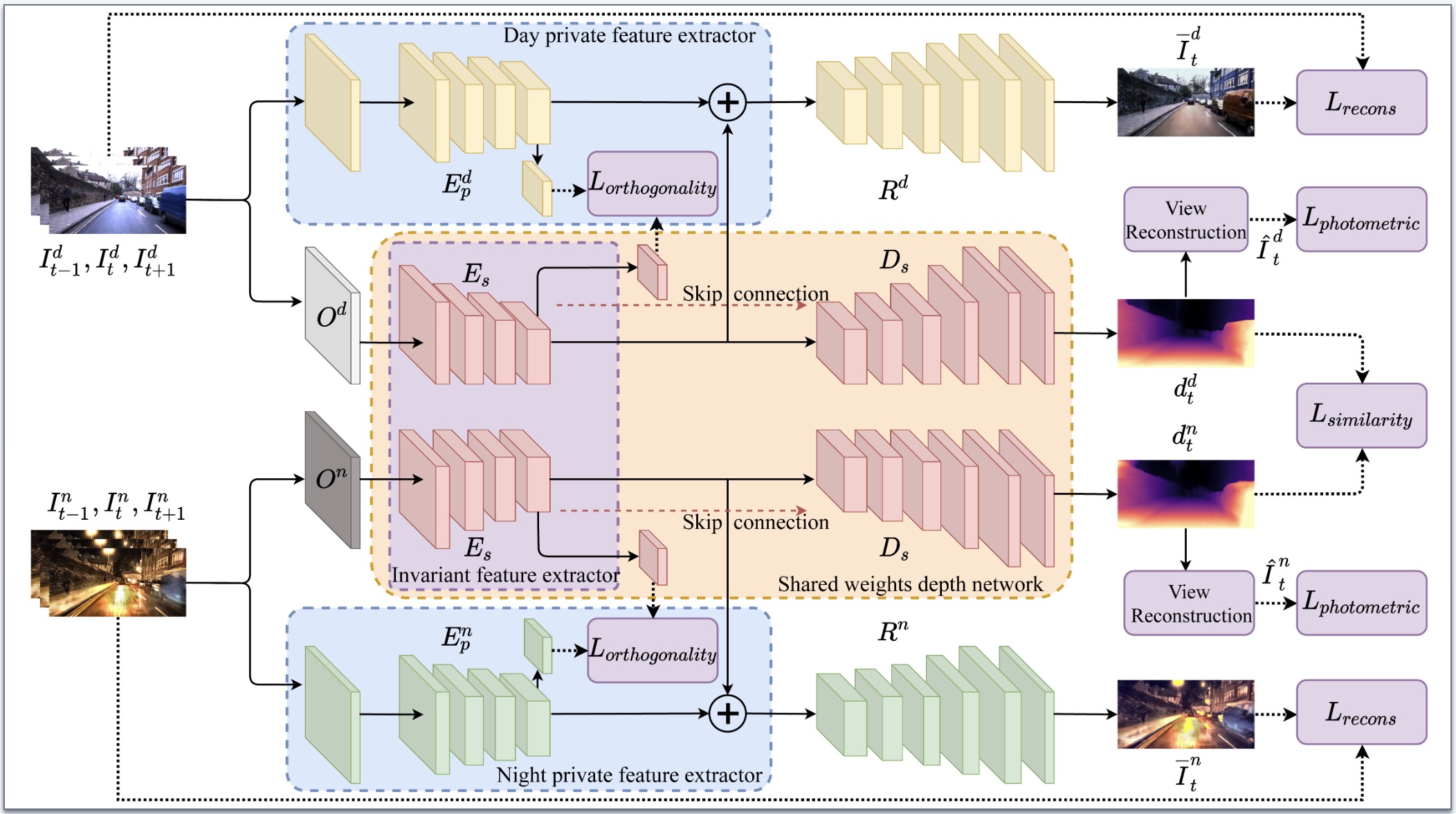
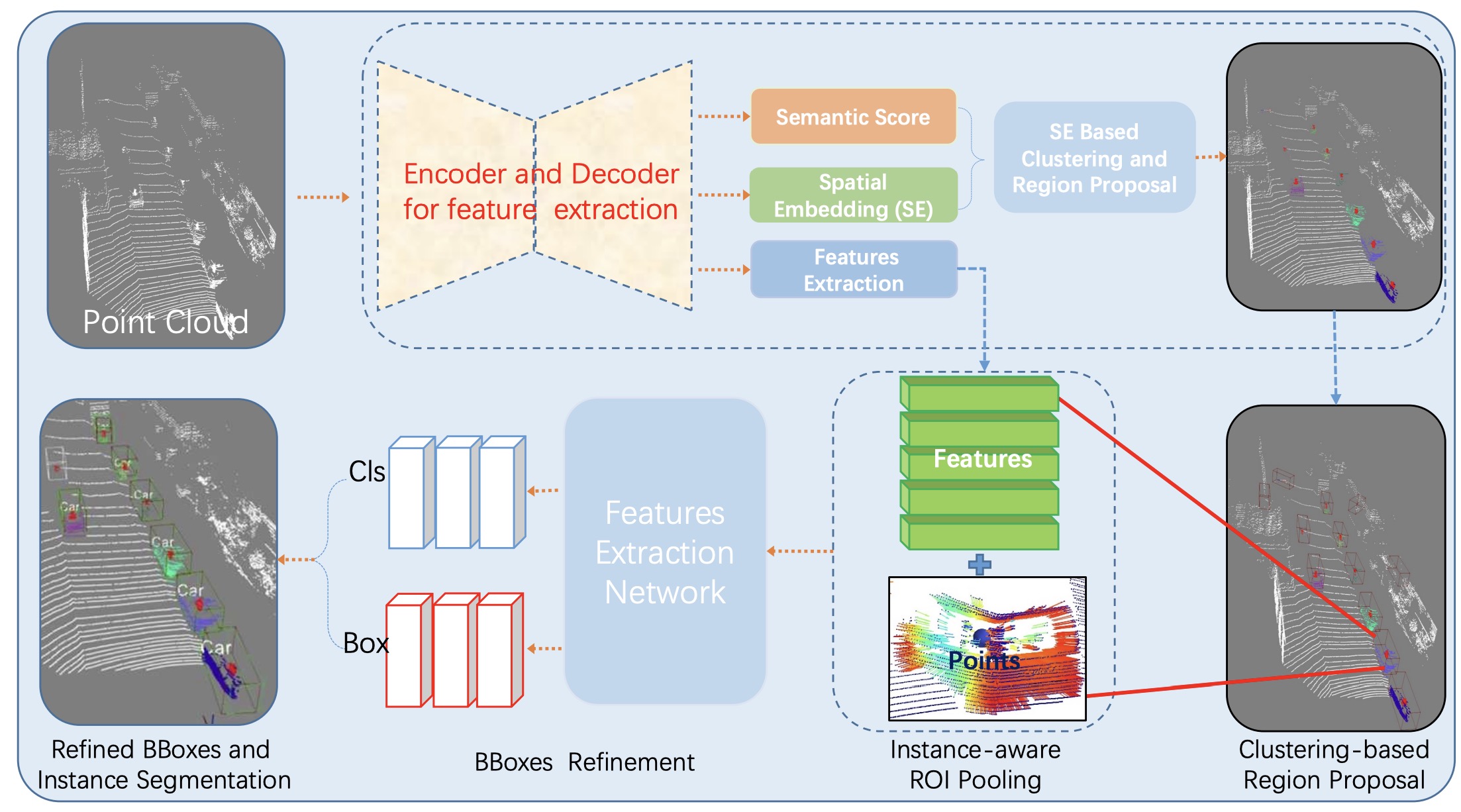
Joint 3d instance segmentation and object detection for autonomous driving
Lina Liu, Xibin Song, Mengmeng Wang, Yong Liu, Liangjun Zhang Corresponding author pdf - ICCV (2021) We propose a domain-separated network for self-supervised depth estimation of all-day images. |
|
Joint 3d instance segmentation and object detection for autonomous driving
Dingfu Zhou, Jin Fang, Xibin Song, Liu Liu, Junbo Yin, Yuchao Dai, Hongdong Li, Ruigang Yang Corresponding author pdf - CVPR (2020) We propose a simple but practical detection framework to jointly predict the 3D BBox and instance segmentation. |
|
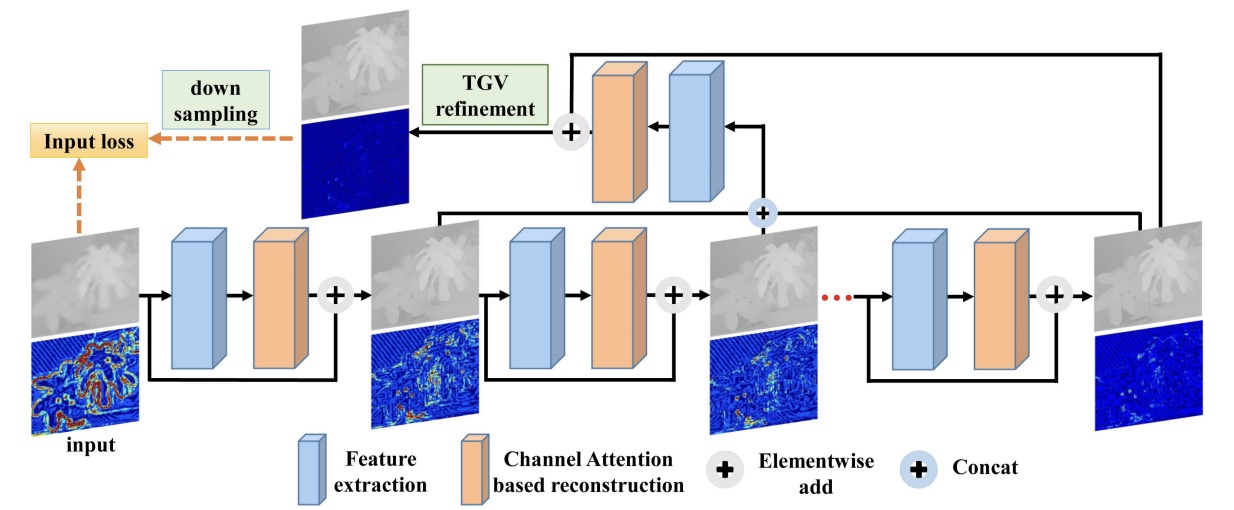
Channel attention based iterative residual learning for depth map super-resolution
Xibin Song, Yuchao Dai, Dingfu Zhou, Liu Liu, Junbo Yin, Wei Li, Hongdong Li, Ruigang Yang pdf - CVPR (2020) We propose a new framework for real-world DSR, which consists of four modules : 1) An iterative residual learning module with deep supervision to learn effective high-frequency components of depth maps in a coarse-to-fine manner; 2) A channel attention strategy to enhance channels with abundant high-frequency components; 3) A multi-stage fusion module to effectively reexploit the results in the coarse-to-fine process; and 4) A depth refinement module to improve the depth map by TGV regularization and input loss. |

|
Apollocar3d: A large 3d car instance understanding benchmark for autonomous driving
Xibin Song, Peng Wang, Dingfu Zhou, Rui Zhu, Chenye Guan, Yuchao Dai, Hao Su, Hongdong Li, Ruigang Yang pdf - CVPR (2019) In this paper, we contribute the first largescale database suitable for 3D car instance understanding – ApolloCar3D. |
|
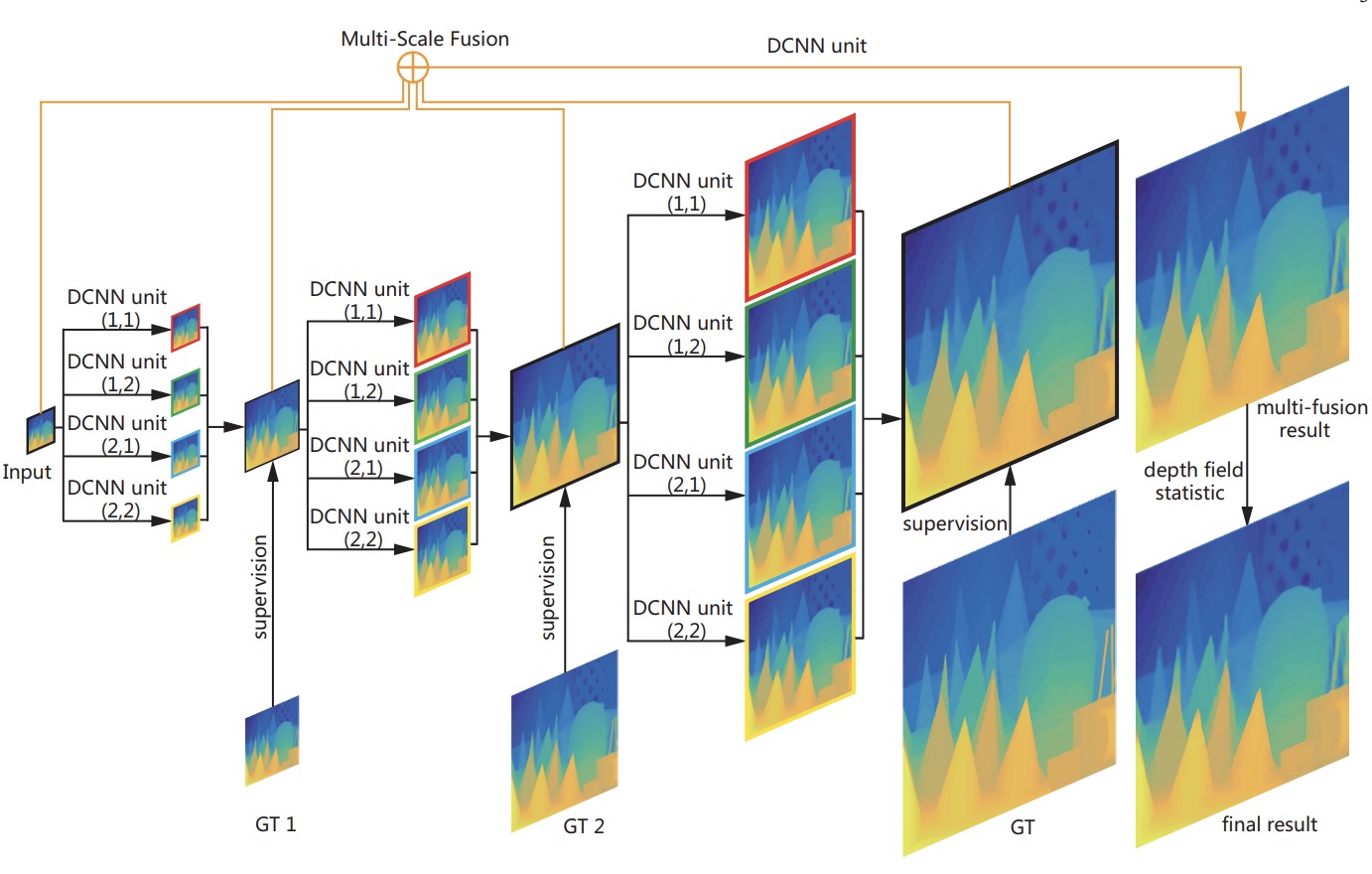
Deeply supervised depth map super-resolution as novel view synthesis
Xibin Song, Yuchao Dai, Xueying Qin Xibin Song, Yuchao Dai, Xueying Qin pdf - IEEE Transactions on circuits and systems for video technology (2018) First, we propose to represent the task of depth map super-resolution as a series of novel view synthesis sub-tasks. The novel view synthesis sub-task aims at generating (synthesizing) a depth map from different camera pose, which could be learned in parallel. Second, to handle large up-sampling factors, we present a deeply supervised network structure to enforce strong supervision in each stage of the network. Third, a multi-scale fusion strategy is proposed to effectively exploit the feature maps at different scales and handle the blocking effect. |